Pythonを使ったSharePointサイトscraping
日本の会社だと社外とはproxyで隔絶され、Windowsサーバーに囲まれている人も多いかと思います。そんな時に社内サイトをWebScrapingしようとした時に役に立つ(?)情報をまとめました。
目次
SharepointをWebScrapingする
ウチの会社ではSharepointをGroupwareとして使っています。
「そんなもん使うなよ」というツッコミは無しでお願いします(^^; 僕が決めたわけじゃないので。
で、部門でSharePoint上に社内お問い合わせシステムを作って運用しています。
ところが、お問い合わせ一覧まではデータ取得できるのですが、やり取り詳細は取得できないという謎仕様。
まぁ、1件のお問い合わせはn件の質問&m件の回答で出来上がっているので、単純にCSV抽出できないのは分からなくもないですが。
1件1件、Webを開いてお問い合わせ内容をコピー&ペーストしないといけないようです。
「んなバカな」
嫌になったのでPythonをイチから勉強して抽出することに。
Python,WebScrapingで検索すると「requestsでhtmlを取得して、BeautifulSoupにかけてやればとれるよん」って簡単に書いてあるので、試してみます。
準備編)環境を整える ー認証proxyの乗り越え方
なにはともあれ、Pythonの環境を整えないといけません。選択肢としては2つ。
- Pythonをそのまま入れる
- Anacondaを入れる
Anaconda自体は、Pythonに数理計算や仮想環境・開発環境などを入れ込んだDistributionという扱いです。正直、WebScrapingの目的からすると「大きすぎるハンマー」に近いのですが、世の中機械学習全盛。
周りはAnacondaだらけだったので、Anacondaに方針転換。
「聞ける人が居る」というのは大事です(^^;
install自体はFullパッケージが落とせるので問題ないのですが、Pythonは豊富なライブラリをNetworkから入手して利用できるのが強みです。ライブラリを入手するにはネットワークアクセスが要るのですが、なにぶん会社内なのでproxyを通してアクセスしないといけません。
Pythonでライブラリを導入するためにはpipコマンドを使います。
まず、ここでproxyを乗り越える必要があります。
pip installの場合のproxyの乗り越え方
・proxy認証がない場合
|
1 |
pip install [ライブラリ名] --proxy=http://proxy.mycompany.com:[port] |
・proxy認証がある場合
|
1 |
pip install [ライブラリ名] --proxy=http://"[ID]:[password]"@proxy.mycompany.com:[port] |
proxyに認証がある場合は、ID/passwordを書いてやる必要があります。
[ID]:[password]@[サーバー名] というのは昔からある記法なのですが、ID,passwordに@が含まれる場合は、””で囲ってやらないといけません。
以下、認証がある物として記載しますので、認証がない場合は、[ID]:[password]@は省略してください。
Anacondaを使っている場合は、Anaconda全体の環境変数にproxyを覚えさせる必要があります。
インストールしたディレクトリに.condarcというファイルを置いて、そこに環境変数を書いてやる方法。
Anacondaの推奨は「ユーザ毎にインストール」で、Defaultのインストールディレクトリは下記になります。
|
1 |
C:\Users\[ユーザ名]\Anaconda3 |
ユーザ名直下は止してくれよ、と思いますがうまく動かなかった場合に差分を探すのが厄介なのでとりあえず合わせておきます。
Windowsでは、最初に「.」があるファイルは作れないので、テキストエディタで別名でファイルを作ってから、renコマンドでリネームします。
ファイルの中には、以下を入れます。
|
1 2 3 |
proxy_servers: http: http://[ID]:[password]@proxy.mycompany.com:[port] https: https://[ID]:[password]@proxy.mycompany.com:[port] |
こちらは、@が含まれていても””で括ったら逆にエラーがでました。わかりにくい (T_T)
これで、
|
1 |
Conda install Requests |
とやったらinstallが通った。
…と思ったら「upgradeするけど、いい?」と聞かれた。Anacondaの場合は良く使われるライブラリは導入済みでinstallされるらしいです。
無駄な時間を費やした orz
第一ステップ)Webページの要素を取得する
WebScrapingの基礎としては「NikkeiもしくはYahoo!ファイナンスから、Nikkei225を取ってきましょう」というのが題材になっている。そういうのが需要としてあるんでしょうね。実際株価データは有償ですし。
Nikkei225まで辿り着くのが目的ではないので、まずはTitleだけとってやります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import requests from bs4 import BeautifulSoup url = "http://www.nikkei.com/" response = requests.get(url) #スクレイピングしたページデータを整形する soup = BeautifulSoup(response.text, 'html.parser') # タイトル要素を取得する title_tag = soup.title # 要素の文字列を取得する title = title_tag.string # タイトル要素を出力 print(title_tag) # タイトルの文字列を出力 print(title) |
実行したところ、これもproxyが要るらしい。
この場合、OSの環境変数にproxyを設定しましょう、というのが常道。
|
1 2 |
export HTTP_PROXY="http://"[ID]:[password]"@proxy.mycompany.com:[port]" export HTTPS_PROXY="https://"[ID]:[password]"@proxy.mycompany.com:[port]" |
って、exportはlinux(unix)の環境設定コマンドですがな…
Windowsの場合はこちら:
|
1 2 |
set HTTP_PROXY=http://[ID]:[password]@proxy.mycompany.com:[port] set HTTPS_PROXY=https://[ID]:[password]@proxy.mycompany.com:[port] |
Windowsの場合、””で括ってやったら動きませんでした…
Windowsのコマンドプロンプトはほんと融通が効かないので苦労します。できる事ならLinux用意した方が、運用は楽だと思いますよ。弊社は無理ですが(T_T)
もう一つ、requestsにproxies引数を渡してやる方法があります。
そうすると、ソースが書き換わって下記になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import requests from bs4 import BeautifulSoup proxies = { 'http': 'http://"[ID]:[password]"@proxy.mycompany.com:[port]', 'https': 'http://"[ID]:[password]"@proxy.mycompany.com:[port]', } url = "http://www.nikkei.com/" response = requests.get(url) #response = requests.get(url,proxies=proxies) #スクレイピングしたページデータを整形する soup = BeautifulSoup(response.text, 'html.parser') # タイトル要素を取得する title_tag = soup.title # 要素の文字列を取得する title = title_tag.string # タイトル要素を出力 print(title_tag) # タイトルの文字列を出力 print(title) |
Windowsの場合は面倒でもこちらのほうが堅いかも。
ちなみに、社内サーバにアクセスするときにはproxy要らないので、社内サーバで試したら逆にエラーが出たのはないしょ。
うん、第一ステップ要らなかったね。
第二ステップ)Web認証の乗り越え方
いよいよ社内のサーバで試します。
url変数の社内のサーバに書き換えて試すと、こんどはWeb認証で引っかかります。
調べると、RequestsモジュールはBasic認証かフォーム認証しか通らない。SharePointなので、当然のようにActiveDirectory認証。
ActiveDirectory認証通すためには、Credentialオブジェクトを使えばっていう記憶があったので検索。すると、.NetASPとかVBScriptとかしか情報がhitしない。
っていうか、Credentialオブジェクト自体.NETFrameworkのオブジェクトです(^_^;
それはそれでScrapingの情報が乏しいし、対話interfaceの無い言語でやるとただでさえ生産性の低い開発作業が滞りかねない。
色々なやんだ挙句、「NTLM認証通せば行ける」らしいという情報が見つかる。
|
1 |
Kerberos認証が使えたら使う →使えない場合はNTLM認証でチャレンジ |
ってことだと思うんですが、「動いたソースが正義」です。
いやあ、仕組みを勉強すると思い込みが強くなりますね。目から鱗でした。
参考).NET Frameworkの認証解説ページ
NTLM 認証および Kerberos 認証
https://docs.microsoft.com/ja-jp/dotnet/framework/network-programming/ntlm-and-kerberos-authentication
NTLM認証が喋れるライブラリもいくつかありました。requestsを補完するらしいこいつを選択。
参考)GIT-Hubのrequests-ntlm
https://github.com/requests/requests-ntlm
そんなことで、NTLM認証を使って、IISの認証を通すためのソース
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests_ntlm import HttpNtlmAuth #対象ページへアクセス #url = '(社内サイトのURL)' username = '(ドメイン名)\\(ユーザ名)' password = '(パスワード)' response = requests.get(url, auth=HttpNtlmAuth(username, password)) #スクレイピングしたページデータを整形する soup = BeautifulSoup(response.text, 'html.parser') # タイトル要素を取得する title_tag = soup.title # 要素の文字列を取得する title = title_tag.string # タイトル要素を出力 print(title_tag) # タイトルの文字列を出力 print(title) |
タイトルが取れた、と思って教科書通り要素を調べて取得しようとするも、うまく取れない。
あれー?と思って下記を入れてソースをみてみました。
|
1 2 3 4 5 |
#print (response.text) f = open('C:\script\html.txt', 'w') # 書き込みモードで開く f.writelines(response.text) f.close() |
大量のjavaScriptソースと、最後の方に見覚えのあるnoscriptタグが。
あー、つまりRequests使って取れるのはScript実行前のhtmlソースなので、BeautifulSoupに入れてやっても、Script実行後のサイト内容は、とれないってことみたいです。
第三ステップ)社内の動的サイトの要素を取得する
動的サイト,Scrapingで検索すると、seleniumとWebDriverを使ってデータを取得すればいい、と出てきます。
ステップ3−1)SeleniumとWebDriverを準備する
selenium自体は、Webの自動テストをするためにブラウザを自動操作するものだそうです。
なので、各種のWebを外側から操作するのがseleniumで、ブラウザに応じたドライバが必要です。Firefoxは拡張機能で対応できるので、ドライバが要らないらしいです。
seleniumはAnacondaの初期インストールに入っていなかったので、installします。
|
1 |
conda install selenium |
Chromeだと、ActiveDirectoryでログインしたWindows端末からパススルー認証できたなと思いつき、今回はChromeを使うことにします。
Chromeの場合は、Googleからドライバが配布されています。
Google公式サイト
https://sites.google.com/a/chromium.org/chromedriver/
ここからzipファイルを落として展開し、展開したところにpathを通します。pathってなに?って方はAnaconda3フォルダにコピーしとけば大丈夫(^_^;
ステップ3−2)取得したい要素の場所を調べる
Webの画面上で、取得したい要素がどんな名前で特定できるのかを調べる必要があります。自動で吐かれるjavascriptは人間様が読めるシロモノではないので、これが一番たいへんです(T_T)
検索する手段としては、cssのclass,id,xpathなどがあります。
|
1 2 3 4 5 6 |
<span class="n"><span class="c"># classでの指定</span> driver</span><span class="o">.</span><span class="n">find_element_by_class_name</span><span class="p">(</span><span class="s">"classname"</span><span class="p">)</span> <span class="c"># idでの指定</span> <span class="n">driver</span><span class="o">.</span><span class="n">find_element_by_id</span><span class="p">(</span><span class="s">"id"</span><span class="p">)</span> <span class="c"># xpathでの指定</span> <span class="n">driver</span><span class="o">.</span><span class="n">find_element_by_xpath</span><span class="p">(</span><span class="s">"xpath"</span><span class="p">)</span> |
最近のブラウザ(Chrome,Saferi,Edgeなど)であれば、要素をしらべることができます。今回使っているChromeの場合、右クリック→検証をクリックします。
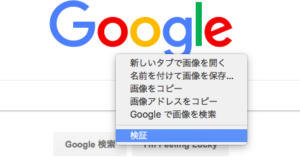
そうすると、ソースを表示した上で、その要素の該当部分まで飛んでくれます。
必要な部分をソースを右クリックしてCopyを選ぶとCopy selectorやCopy Xpathといったメニューが出てきます。
自動で吐かれるscriptはネストが深いのでXpathがいいんじゃないかなと思います。
Xpathは、htmlのrootからその要素に至るまでのxmlタグを/で繋いだもの、という何となくの理解でいいと思います。
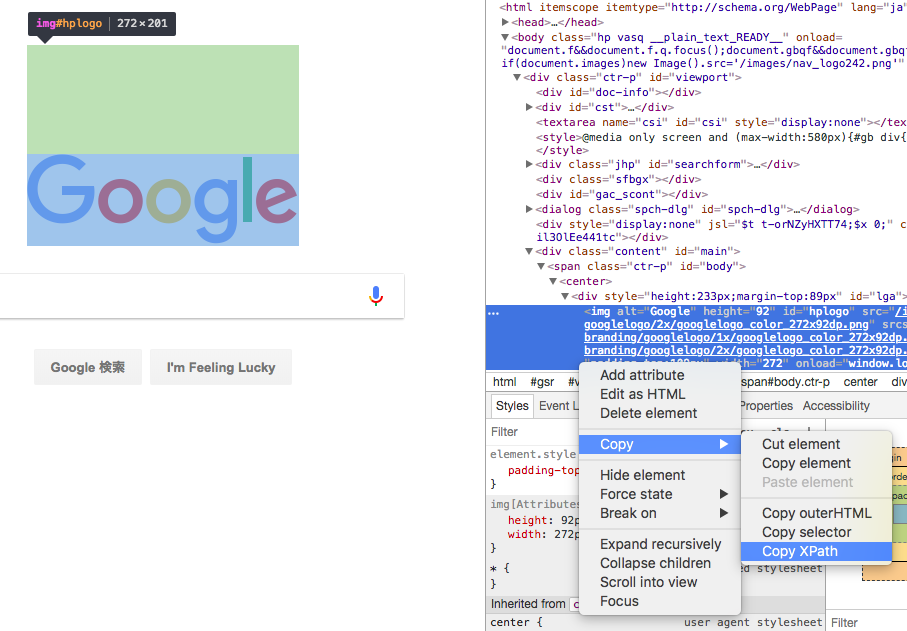
必要な情報が取れているどうかは試すしかありません。対話型インターフェイスを使って、内容を表示させて、試行錯誤です。
Anacondaであれば、jupiter notebookというツールを使えばいいと思います。
下記ソースを入れてみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from selenium import webdriver #1)WebDriverを開く driver = webdriver.Chrome() #2)取得したいサイトのurlを指定 url = 'http://(データを取得したい社内サイト) #3)取得したいサイトを開く。Chromeのウィンドウが開く driver.get(url) #4)要素を指定して、Contentオブジェクトに代入 Content=driver.find_element_by_xpath('コピーしたxpathをペースト') #5)contentで取れた内容を確認 Content.text |
要素の指定がうまく行っていなければ、#4〜#5を繰り返して指定の方法を探ります。
xpathを解析してくれるnokogiriというツールも有るそうなんですが、今回は使いませんでした。
ステップ3−3)要素を繰り返し取得して、ファイルに吐き出す
sharepointのListは管理番号IDを引数にしたURLで詳細を呼び出せるので、必要な番号範囲をLoopで回してデータをCSVに吐き出します。
ここは、プログラムがわかっている方であれば書けると思います。参考まで載っけておきます
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
# coding: utf-8 import csv from selenium import webdriver import codecs import sys # 出力先ファイルを書き込みモードで開く #UTF-8で出力される。取得後にS-JIS変換する必要あり。 f = open('c:\Users\[user名]\documents\contents.csv', 'w', encoding='UTF-8',newline='') writer = csv.writer(f, lineterminator='\n') #WebDriverを開く driver = webdriver.Chrome() #取得する最大管理番号 i=999 while < 1: url = 'http://(sharepointのlistページ)&ID=' + str(i) print(str(i)) driver.get(url) title =driver.title print(title) #IDに対応する内容があるかどうかチェックする #該当する管理番号が登録されていなければ、エラーが返る if title=='エラー' : #エラー内容を取得 ErrorMessage=driver.find_element_by_xpath('//*[@id="xxxxx"]') print(ErrorMessage.text) content = ErrorMessage.text else: #ブラウザで表示されている内容から、xpathで場所を指定して #今回はtableの5行目行を取得 ContentRow=driver.find_element_by_xpath('//*[@id="xxxxx"]/table/tbody/tr[5]') print(ContentRow.text) content = ContentRow.text #画面上の見やすさのため空行を出力 print('') #ファイルにCSV出力 writer.writerow([str(i),title,content]) i=i-1 f.close() driver.close() |
必要な管理番号範囲を引数にしたほうが良いかな、と思いますが何度も分析するとは思えないので、次取得する必要が出た時に改造することにします。
社内環境でSharepointサーバーをScrapingする方法まとめ
- Anacondaをインストールすれば、大概のライブラリはPre-installされている。
- 認証済みのWindows端末からChromeでアクセスすれば、認証はパススルー。
- ChromeのwebdriverはGoogleから入手できる。展開してpathを通せばオッケー。
- 取得したいWeb要素をChromeの検証機能でxpathを調べ、xpathでfind
あれ?NTLM認証も必要なかった?

